The Bank-of-Allen Project:
The OO-Design Process from Conception to Modeling.
(c) 2003, Allen I. Holub, All rights reserved.
Introduction
This document is a work in progress. The Bank-of-Allen project originally appeared as a series of articles on the IBM Developerworks web site, starting in July of 2000. Prior to that, I'd used it for a couple years in OO-Design classes that I taught both privately and through the University of California, Berkeley, Extension.
I found that by far the best way to teach OO was to demonstrate the entire process from front to back, and the Bank of Allen was a good way to do that. My original intent was to go all the way from conception to implementation in the series, but a few problems emerged: The stock market crashed, and IBM stopped accepting content for their site, but this happened to happen at an opportune time. Put simply, I was stuck. In class, I'd have people read through the document you have before you, and then I'd demonstrate how to go from use cases to UML on the board. I found it surprisingly difficult to capture this process on paper (which might explain why there are no good books on the subject).
The modeling process is incredibly dynamic. You have many things going on at once (dynamic modeling, static modeling, UI refinement, sometimes some coding), and all of these activities create artifacts that inform the other activities. For example, you often find something in dynamic modeling that affects the UI (and vice versa). Consequently, it's almost impossible to capture the process on paper—a fundamentally linear medium—in a way that shows you how the process really works. OO modeling, for the time being, is still an oral tradition, passed from OO-master to disciple along with the OO-designer secret handshake.
At some point, I intend to solve the problem by making a video. In the interim, there are a few alternatives:
- You can do it the hard way, read a bunch of books, and then try it. I don't really recommend this approach since you'll spend about a year spinning your wheels producing a bad design. Most designs are created in exactly this way, and many of the projects that derive from these designs fail (or the design is simply discarded) because the designs are no good.
- You can hire a mentor. (That's one of the things that I do for
a living—contact me through
www.holub.com
allen if you're
interested).
A good mentor should be able to teach you the process, and then
guide you through the design of your next product from start to
finish. The mentor should be both an expert-level designer
and programmer as well as a good teacher.
Simply hiring someone to teach a class isn't the same thing as mentoring, since there's no follow up, no regular assessment of the emerging design, and no day-to-day help when problems emerge. I have taught many stand-alone OO classes, but without the follow-up of a mentoring relationship I usually feel less sanguine about the student's ability to achieve good results. A class or workshop should be part of the development process, not an end in itself. Hiring a company such as Rational to teach a class is particularly ineffective, since classes of this sort tend to be advertising vehicles from the company's products more than educational opportunities. - Hire an architect to do your first the design, implement that design, then design version 2 yourself. (I can do this for you as well.) You then implement the design yourself (with the help of the architect). This way, your first experience with OO is with a comfortable activity: coding. You learn a lot, however, in coding up a quality design. For the next project, you'll do the design yourself (ideally under the guidance of a mentor), but by then you'll have a lot of experience working with OO systems under your belt, and the resulting design will be a reasonable quality.
- Consider XP (Extreme Programming). The primary design tool for XP is use-case analysis (which the XP folks call "story cards"). Many XP shops implement directly from the use cases without any static or dynamic modeling at all. XP can work well, provided that your project is small enough, that your programmers are sufficiently diciplined and are well versed in the structural fundamentals of OO such as design patterns, and that you acutally do XP (all of it, not just the bits that appeal to you).
- Attend my OO-Design workshop. I do public workshops four times a year, and present them in-house all the time. (Find information on my web site: www.holub.com.) In the course of the workshop, you'll spend several days working under my close supervision in a small team, actually developing a design from scratch. In all honesty, the workshop isn't a good as a full-blown mentoring relationship, but it's vastly better than your normal OO-design class. If you have an in-house expert who can act as a mentor during development, then it can also make sense to do a workshop to get people started, and then have your in-house architect do the follow-up work.
Don't get discouraged. Design is hard work.
It takes as long to become
a good designer as it does to become a good programmer—there's a lot
to learn.
Nonetheless,
if you want to do high quality work in minimal time, there's
no alternative to good up-front design.
The OO Design Process
Getting Started
My intent in this column is to provide a detailed look at the OO (object-oriented) design and development process by actually doing it. This column is more of a journey than an event—it will take many months to get through the entire process. We'll start out with requirements gathering, move through analysis to design, then do a Java implementation of that design. When we're done, you'll have a complete case history of an OO program literally from start to finish. I'll talk a lot about the underlying theory, but the central focus will be real examples of how that theory is applied.
Before we get started in earnest next month, I've a few warnings,
comments, and observations that will give you a feel for my own
prejudices opinions on the subject of design.
OO Isn't About Structure
First, at its core, object orientation is not at all about derivation, class hierarchies, UML, Java, and so forth. These are tools that the OO designer puts to use in order to structure the analysis, the design, and the implementation, but they aren't central to what makes an OO program object oriented. I'll certainly use all of these structural parts of object orientation as the process unfolds, but the first few columns in particular may seem mysterious to you if you equate implementation structure with object orientation. The key concept of object orientation is modeling, so before we can do anything, we need to decide what we're going to model. Adele Goldberg recounts a story told to the congregation by a rabbi at the start of a new year:1
A rabbi boarded a train, one on which he often rode and one whose conductor, therefore, recognized him. The rabbi reached into his coat pocket for his ticket. Not finding it, he began a search of his belongings. The conductor stopped him: "Rabbi, I know you must have the ticket somewhere. Don't bother searching now. You can send it later, when you do find it." But the rabbi kept searching. When approached by the conductor yet again, the rabbi replied: "You do not understand. I know you trust me for the ticket. But—where am I going?All too many projects fail because they start out without a clear idea of where they're going. The OO process tries to solve this problem by defining the problem to be solved as the first step, and it will take me a few columns to do that in sufficient detail that the actual analysis and design phase can proceed. That is, before you can analyze, you have to have something to analyze.
Feel Free to Customize
Next, the process I'm describing is the one that I use personally.
I don't intend these articles to be definitive.
It turns out that the way
that I work is similar to Booch, Rumbaugh, and Jacobsen's RUP
(Rational Unified Approach),2
but that's not due to any planning on my part.
Things just worked out that way.
I also lean in the direction
of Kent Beck's so-called Extreme Programming (XP),3
but again, this
is just a matter of chance. I'd expect that my processes that I
will have to be personalized by you to make them workable.
Since the literature is singularly
devoid of a hands-on discussion of any
process whatever, it seemed that a discussion of any process,
even if it's a personal one, would be helpful.
Please don't argue with me about whether I'm
"right" or not, just bear in mind that what I do does work for me,
and that there's absolutely nothing wrong with changing
what I do in a way that makes it work better for you.
Tools, or The Lack Thereof
A note on OO-design tools is also in order. Someone once told me that he couldn't do OO because he couldn't afford it: "Rose costs $2500/seat and you obviously can't do design without Rose!" The "Rose" in question is an OO CASE (Computer-Aided Software Engineering) tool sold by Rational Software. (I might review OO-CASE tools in a future column.) Putting aside the fact that Rose is neither the most cost effective, the most capable, nor the most usable of the tools available, the fact is that I often work effectively with nothing more high tech than a pencil and paper—no computer at all.
As we'll see in upcoming columns, the process of OO Design is really a form of semantic analysis. It has more in common with formal linguistics than traditional procedural-design techniques. I've found that computers often get in the way of this analysis. You spend more time messing around with the tool than you spend getting work done. To make matters worse, many of these tools (Rose among them) are tied to hideous draconian licence managers that prevent you from running the tool on a laptop that's not connected via a network to the license manager. When I use a computer at all, I typically use a drawing program (Visio) not a CASE tool. (Which is not to say that I think that Visio is a particularly good tool for this purpose, either—I just happen to own a copy. I use my own templates not the built-in UML support.4
The point I'm trying to make is that design has nothing to do with tools. Design is a way to crystallize your own thinking on complex topics, it's a way to make sure that you've covered as many bases as possible before you start to code, and it's a way to communicate with other programmers about the code.
Since communication is really central here, any tool that doesn't facilitate communication is virtually worthless. You are not communicating if you are sitting alone in your office in front of a computer-based CASE tool.
The choice of a CASE tool is irrelevant—I don't use any of them on a regular basis—though they can be helpful with larger projects. They all generate miserable code, though, so I don't use the code-generation or "round-trip engineering" features of these tools. In any event, the notion of round-trip engineering—in which you create a design, generate code, hack up the code, then reverse-engineer the hack back into a "design" is a fundamentally flawed notion. Design is an inherently one-way process. You design, then implement from the design. You modify the design, then implement the modifications. Most of these tools create incorrect designs in any event, since they can't adequately reverse engineer the dynamic behavior of the program simply by looking at the code.
A decent drawing program and a word processor is more
than sufficient for our purposes.
The Design Environment and Tools
Design is always a group activity. At minimum, you'll need a programmer, a tester, a customer (or somebody who understands the domain of the problem thoroughly), somebody who can write high-quality English, and a UI designer. You'll ideally have some sort of clerical support as well: someone who takes notes and creates transcripts, someone who enters hand sketches into drawing programs, etc. You can get by without this level of support, of course, but the design will come together more slowly since the team members won't be able to focus.
All of these people have to be together to work effectively and all of them have to be present all the time. Design is a full-time activity and nobody can afford to be distracted by other activities if you expect to finish in a timely fashion. (Virtual togetherness, using whiteboard software and the like, is a possibility, but you'll need video and audio feeds—so you can see and hear everybody else—as well as the computer if you expect to communicate effectively.)
One of the best design tools you can have is a room designed for that purpose. My ideal design room is a pleasant room—one where you might choose to be. It has plenty of windows (and light). The walls are covered literally floor to ceiling with white board. (You can buy 4x8 sheets of Melamine at Home Depot and screw them onto the wall yourself if you like.) This is not a conference room, toss the conference table and hideously uncomfortable chairs (designed, I think, to make the conferences as short as possible), and replace them with a comfortable couch and a few arm chairs. You'll need a well stocked fridge, and a few small tables that can be moved where they're needed. The main design tool in use will be the white-board marker and eraser, but you'll also want an LCD projector hooked up to a networked machine to make it easy for the group to work together on written documents. Images are transferred from the white board to the computer with a high-res digital camera. In the best of all worlds, you'd combine the design room with an implementation room of the type described by Beck in the XP book mentioned earlier—add a few workstation clusters and some private space for people to be alone when they need to be.
You won't find a space like this in a typical office, so you'll
probably have to make one. Get out a screwdriver, rip up the
cubes, and put one together. If the facilities people don't like
it—tough. What's more important to the success of the company,
producing high-quality software or supporting some idiot's notion of
what a "proper" office should look like?
Design and Architecture
One of the more heinous crimes perpetrated by Microsoft is the introduction of the verb "to architect" into English. (At least, the first time I ever heard the word used in this way was in a talk by Microsoft's Paul Maritz at a "Professional Development Conference.") Architects design buildings; they do not "architect" them. The reason I bring up this malapropism is that this specific abuse of the language artificially implies that a building's architect and a computer program's architect are engaged in fundamentally different activities. I strongly believe that architecture is architecture, whether you're designing a building or whether you're designing software. For example, Christopher Alexander—an architect of buildings—conceived the notion of a design pattern,5 and design patterns are fundamental to contemporary software architecture.
If you were to walk up to a contractor and say: "I want you to build me a house, how much will it cost and when will you have it finished?" he'd look at you as if you were crazy. Programmers definitively answer equally vague questions all the time, however, and people wonder why software is rarely delivered on time and within budget. Moreover, no contractor would even consider starting construction on something as complex as a building without some sort of plan. Plans developed by contractors themselves will typically not yield as nice a building as those developed by architects, however. Contractors will naturally design for ease of construction and low cost, which are not necessarily the best choices for a building that you plan to live in. Programmers, similarly, are typically not the best equipped people for designing programs, since they have different priorities than the end user. This is not to say that a good architect won't know how to construct what they're designing—I'm convinced that the best software architects are also the best programmers—but that design and construction are different activities and need not necessarily be performed by the same people.
The first step of designing a building is meeting with the client and figuring out how the building is going to be used. Architects are interested in the clients aesthetics, of course, but they ask many other questions. What are your hobbies? (Do you need specialized space for them) Are there pets? (Do you want a cat-feeding station in the kitchen?) Do you have children? (Do they need a playroom?) How many? (How big should the playroom be?) All of these things influence the design of a building. If an activity that's going to be performed in the building is unfamiliar to the architect, then he or she will have to learn something about that activity to arrive at a satisfactory design. If the client is a koi keeper, for example, the architect is going to have to learn about pond technology—not at the level of a koi keeper (a "domain expert" in design parlance), but at least at the level of a well informed layperson. Note that the emphasis is on how the building will be used. Construction considerations, though they're always in the back of the architect's mind and do influence the design, are not primary.
The next step is sketches of potential buildings, rooms, grounds, and so forth. Lots change at this point, rooms move around, change shape, fixtures and walls are added and removed. Only when the clients needs are correctly reflected by the sketches will a set of "final" plans be created, but even these plans aren't really final. They're submitted to contractors and engineers, all of whom request changes, all of which (if they're visible, at least, or affect cost or schedule) are run by the client. Only then does construction begin.
The level of detail in the plans is also relevant. Much of the design work is done as the building is being constructed. The architect shows where the walls go, but the contractor figures out the details—stud placement, framing for the windows and doors, etc. The architect shows where the electrical outlets go, but the electrician figures out how to route the wires, where the electrical entrance goes, and so forth. The plans show the drains and plumbing fixtures, but the plumber figures out how to route the pipes and hook up to the water main and sewer. That's not to say that these parts of the building aren't designed, but rather that this part of the design is done by the specialist who's doing the construction. This design work is often done informally—on the site as work progresses. Moreover most of the design artifacts—scraps of paper with drawings on them or sketches made on studs inside the wall—are discarded since they aren't relevant once the object is built. When the specialist needs to do something that effects other specialists or the overall design of the building, the the ball is passed back to the architect, who modifies the master plans (after consulting the client).
Given simple and complex ways to solve the same problem, the simple
way is always used provided that it doesn't impact the integrity or
aesthetic of the structure. Nonetheless, sometimes the only way to do
something is complicated.
It's also important to note that the level of detail required before
construction begins is a function of the complexity of the structure.
You can design a dog house on a napkin. A house requires more detail.
In a skyscraper, virtually every pipe and electrical conduit is
designed (though the positions of the walls sometimes aren't!).
Summing Up
The process I just described is essentially the same process that I use to create software, and it's that process that this column will demonstrate piece by piece. Here are the rough steps—I'll go into lots of detail in future columns so that the detail can be put into context. Many of these operations actually occur in parallel, and we'll see that in upcoming months:
- Learn about the problem domain.
- Interview the users and determine their needs and goals.
- Develop the "Problem Statement."
- Design the user interface.
- Develop the "Use Cases."
- Rough out a draft static model.
- Develop the dynamic model while refining the static model
- Implement
As I go through these steps, I intend to capture the entire process as it occurs, including the mistakes I make and how I fix them. By the time we're done, you'll have a complete (and realistic) picture of the design process.
So, let's begin...
The Design Process
This month I'll start actually designing a piece of software.
I wanted a project that would be nontrivial, yet compact enough that
we can do it in a reasonable timeframe. I also wanted to use
a program that was honestly useful, rather than a pure pedagogic
exercise.
I decided on a piece of educational software called the Bank of Allen6
Over the course of several months, I'll present a complete design
and (Java) implementation of the program, so you'll be able to
see the whole process, from start to finish. I've also (deliberately) not
edited my mistakes out of the process so that you'll have an honest
look at the way things happen in the real world. So let's get started.
OO Requirements Gathering
I unfortunately can't remember exactly where I read it, but I once came across the statistic that something like 60% of the programs written every year are discarded within a few months of completion, not because the program doesn't work, but because it doesn't do anything useful. The resulting loss of productivity is staggering, of course. Moreover, much of this code is produced by shops that are very "high-ceremony"—they generate enormous volumes of paper in the pursuit of what they think is design. Clearly what they're doing isn't working,7 but equally clearly, proceeding with no design at all doesn't work either. Given the failure rate of high-tech start-up companies, I'd guess that the percentage is now even higher than 60%.
I strongly believe that one of the main reasons for this failure is, as I mentioned last month, the fact that most programmers embark on the journey of software development without a clear idea of where they're going. For a program to be useful, it's essential to ask someone who's going to use it what it has to do. Often this stage is omitted entirely. Often, self-appointed proxies for the real users (such as salespeople) make up fantasies which they call requirements. Often, real users are indeed consulted, but in such a way that they don't or can't make their needs known. Our first task, then, is to figure out what has to be done, not how to do it. (Most programmers immediately focus on the how: what database will we use? what will the data model look like? what will the UI look like? what are the data structure? etc. The how is irrelevant at this stage—try to suppress the impulse.)
In OO parlance, this first stab at problem definition is called a formal "Problem Statement," and building one of these will be our task for the next couple months.
In a procedural system, the problem statement is often omitted in favor
of something called
requirements gathering. I prefer the term problem definition since
"requirements gathering" usually carries a lot of incorrect (at least from
the OO perspective) assumptions about what
a "requirement" is and how you go about gathering it.
In a traditional procedural environment, you'd produce a
"Functional Requirements Specification,"
often working
from a list of features provided by some outside third party such as a marketing department.
In fact, often the "requirements" are a fait accompli, over which you have no control.
You'll find that in an OO environment, these sorts of documents—the feature list in particular—are
almost worthless. Those "functional requirements," that provide algorithms and specify
performance requirements will make a useful appendix to the OO deliverables, but they are
not central.
The "functional requirements" that specify UI behavior, workflow, etc., are
virtually worthless, for reasons that we'll see over the next few months.
The Problem statement
Crafting the Problem Statement, then, is always the first step in any design. Your goal, here, is to succinctly, but accurately, state the problem that you're trying to solve. Again, you're interested in what, and why, but not how.
Before you can start defining the problem, you must first learn something about the problem domain, however. Though every OO design team must have a domain expert—ideally an end user—as a team member, the other members of the design team must also know the domain, though not as thoroughly as the expert. You have sufficient domain knowledge when you can hold an intelligent conversation using the vocabulary of the domain itself, without the experts needing to stop and explain what they think of as basic concepts.
Consequently, you must begin any design project with a research phase. If you're doing an accounting program, go take an Accounting 101 class at a local junior college. Again, you don't need to be an expert—that's your user's job—but you do need to be able to hold intelligent conversations with domain experts using their own vocabulary. Without some knowledge of the subject, you won't even know what questions to ask or how to ask them. Do this before you do anything else—don't even attempt a simple problem statement until you understand the domain.
It's critical to the success of the entire design effort that the problem statement be a well-crafted essay. A bunch of bullet points and sentence fragment simply won't do—they rarely capture the subtlety of the problem in any detail, and a hodge-podge of disorganized sound bites tell you nothing about program structure. If you can't say it in clear well-structured English, then you don't understand the problem well enough to design anything. Good grammar is also important. Grammar gives structure and precision to otherwise disorganized thoughts. A good copy editor is an important member of any OO design team.
Not only is it true that if you can't express a problem in well-written English, you simply don't understand the problem, there's something about the writing process itself—the need for accuracy that you typically don't have in conversation—that helps you discover new facets of the problem. I find that the only time that I find myself not being stumped by something when I start coding is when I've written out the problem first. This reasoning applies even to simple method definitions—if you write the comments before you write the code, the coding will go much faster and the code will be less buggy.
The discussion has to be couched entirely in the vocabulary of the problem domain—if you're solving an accounting problem, the problem statement should be written entirely in the vocabulary of accounting. That is, any competent accountant should be able to make sense of the problem statement without having to ask any questions. It is a general rule of thumb about the completeness of a design, that a competent programmer who's familiar with the domain at the level of an intelligent layman must be able to read through the design documents and completely understand both the specific problem being solved and the general solution to that problem. If this level of understanding isn't possible, then the design document isn't complete.
I cannot emphasize too much that a problem statement is not a discussion of a computer program. A problem statement should define the problem itself, not a computer-based solution to the problem. It is a discussion of the real-world problem that your end user is trying to solve. Words like "computer," "menu," "dialog box," "internet," "Worldwide Web," and so forth typically have no place here. A problem statement never contains a sentence like "The system must..." or "We need to write a computer program that..." Writing a computer program might be your problem, but computers are rarely involved in the problem that your end user is struggling with (though they may be involved in the solution). Most problems can be solved perfectly well without computers—though the computer might make the solution easier or faster—and these same problems can be described perfectly well without mentioning computers.
Though you will eventually have to write a description of the computer-based solution, for now we're focusing on the domain-level part of the document. Computer jargon simply has no place here, and any accountant should be able to read our accounting-domain problem statement and understand it without asking questions.
Conversely, solutions to the problem that are part of the problem domain itself should certainly be discussed. All OO systems must model something. If an existing problem has a good solution, and the real problem is that the existing solution can't be performed fast enough by real people, then just model the existing solution. That is, often the automation of an existing manual process is all that's required, and your "problem statement" will be a complete description of that manual process.
One critical thing to identify in a problem statement is the goal of the user. What exactly is the user trying to accomplish? The goal can drastically affect the direction of the solution. (e.g. Is it your goal to schedule a meeting or to maintain a calendar? In the first case, the only place in the program where you might see something that looks like a traditional calendar is in the output.) Alan Cooper, in his book About Face, calls this way of working "goal-directed design."8
You also need to address the desired outcomes. What are the end products of the solving the problem? What information do these end products have to convey? (Note that we're interested in the informational content at this stage, not the physical layout or the way that the content will be presented.)
Insofar as it's possible, ignore the existence of legacy systems. It's rarely the goal of a user to improve a legacy system; rather the user has to get some job done and is coming to you because the legacy system isn't working. Start with a clean sheet.
Don't try to get too formal in the problem statement. Just describe what you want to do as if you were having a conversation with a peer. (I've often been asked "how to I say <something complicated>?". My response is invariably: "Just like that—you just said it.")
Normally, the next step is to have several conversations with real users and domain experts and try to define the problem cogently, then capture the problem on paper using domain vocabulary, then running the problem statement back by your users to make sure you got it right. Thinking that I could skip the interviewing process since I was myself a domain expert (a parent), I just started writing. (It turns out that this I was mistaken in taking this shortcut—more next month.)
So, here's what I came up with:
The Bank-of-AllenTM
One of the best ways to teach kids how to manage money (and how interest works) is by having a bank account. Real banks, however, don't pay enough interest to catch a kid's interest, so to speak. (At a nominal annual rate of 3.5%, $20.00 earns a big $0.72 after a year—not very impressive). Taking a cue from a piece I heard on National Public Radio's "Marketplace," I decided to open the Bank of AllenTM (or BofA), which pays out an effective 5%/month (that's right, per month—60% annually), but compounded daily. At this rate, $20.00 deposited in the Bank of AllenTM earns $15.91 over a year. The Bank of AllenTM otherwise works like a real bank. Kids have their own accounts, over which they have control of everything but the interest rate. They can look at (or print) their passbooks whenever they want. They can make deposits and withdrawals at will.
To make saving more interesting to the kids, the passbooks must show them how much money they're earning from interest in addition to the usual stuff (deposits, withdrawals, running balance).
The kid must also be able to play what-if games with projected interest: "How much money will I have if I don't withdraw any money for two whole months?" The point is to demonstrate that you can make money by not spending it.
There are a few security issues. Only the bank (i.e., the parents) can change the interest rate or set up a new account (and the initial balance). Like a real bank, kids can't make a deposit or withdrawal by modifying their pass books; they have to ask the bank to do it; the bank processes the transaction and updates the passbook. That is, the kid gives money to the bank, which puts it into the account. The bank takes money out of the account, and dispenses it to the kid. (Practically speaking, this means that only parents can make deposits or withdrawals, but parents should process withdrawal requests when asked or the kids will assume that the bank is a ruse for not letting them get at their own money.)
Goals (ranked by importance)
- To teach kids to save money.
- To show how compound interest works.
I don't pretend that this problem statement is complete, but it's a start. In general, a problem statement is not complete if any reasonable questions have not been addressed. This is typically a tremendous amount of detail. A problem statement for an average small program—one that might take a small team six to eight months to implement—can easily get to 80 pages or so before all the details are hashed out. So, I'm sure that what I've done so far is way too brief.
The point of the exercise is to think about as many details as possible before you start coding. You are not trying to bolt things into concrete. Don't pretend that you'll be able to capture all the details up front. Unless you're working in a very static environment, it's nigh on impossible for all of the details to be settled (or even discovered) in advance, and in any event, as the system goes into production and is actually used, the end users themselves will discover things that they hadn't thought about initially. This after-the-fact discovery is natural, and any design methodology that can't handle the late-breaking changes will be too brittle to use in most programming environments. In practice, then, the problem definition will change as the design and implementation evolves. That's why it's so essential to have an end user on the design team: to make sure that you don't break things rather than improve them.
Nonetheless, the initial problem definition should be as complete as possible. Do a complete brain dump to paper. Don't leave out any details, even simple ones. One of the things I do for a living is mentor teams through their first OO design effort, and often I don't get called in until the effort is already underway. Usually, I ask for my clients to send me their design documents so I can prepare for our first meeting, and more often than not I'm told that I'll have to come in an talk in order to fully understand what the problem is. That response sets off all sorts of warning bells. If the problem hasn't been written down in enough detail that an outsider can understand the problem by reading, then I know as a fact that the client probably doesn't understand the problem well enough to start designing. Though I certainly believe that "analysis paralysis" exists, I've never witnessed it; rather, I've seen the opposite: teams who have jumped to coding way to early without sufficient up-front analysis.
Looking back at the incipient problem statement. Notice that I haven't mentioned computers anywhere. I'm describing the problem, not a computer program. The problem domain, here, is parenting, not banking. Consequently, the statement is written for a parent, not a banker, to read.
Also, note the relatively simple structure of the sentences.
Avoid the passive voice and other turgid academic prose
styles like the plague.
A simple declarative sentence (subject/verb/direct-object)
identifies the initiator of an action (the subject), the operation
performed (the verb) and the receiver of the message that requests
the operation (the direct object). The passive voice only identifies
the last two of these three parts. Use "I," "you," and so forth if
whenever it makes sense to do so.
Refining the Problem Definition
This month I'll continue refining the problem statement that I started last month: a piece of educational software called the Bank of Allen9
The next step that I usually take when starting a problem definition is to define a Glossary. In general, terms of art that are immediately recognizable by someone familiar with the domain shouldn't need to be defined, but often a term has an ambiguous meaning, or it's used in a limited way in the current problem, so will need to be explicitly defined.
One "gotcha" in a problem statement is inconsistency. It's essential that the same word not be used to mean two different things, and that two different words never mean the same thing. Your first line of defense is a glossary. Typically, you would not define problem-domain terms here. For example, you wouldn't define things like "credit" or "interest" if the problem domain was accounting. The current problem domain is parenting, however, so terms like "credit" need to be defined precisely.
The glossary is also helpful in our main goal, which is to identify the key problem-level abstractions. Often essential words and concepts appear in the glossary that don't appear in the many body of the problem statement. For example, the definition of "passbook" introduces the notation of a "transaction." (The notion of a transaction turned out to be significant, though I didn't actually come to this realization immediately.)
It's also helpful to add an Implementation Details section to provide a place to remember these details, even though they're not actually part of the problem statement per se. The sorts of things that normally would go in a "Functional Requirements Specification" often go into the implementation-details section.
Here's my first-pass glossary and details:
Glossary
Implementation details:This section is not part of the problem statement per se. It's just things that occur to me while putting together the problem statement that I jot down so I don't forget them.
|
Verify and Refine the Problem Statement
All pleased with myself that I had a reasonable problem statement, the next step was to do a design review. I pressed my wife DJ, who is both a programmer and a domain expert—a parent, into service. She found various minor grammatical problems (which I must confess, I have fixed in the initial statement that you just read), but she found one serious flaw that I hadn't even thought of. "You can't compute interest like that," she pointed out. "If you just divide the monthly interest by the days in the month, but compound it daily, you'll end up with a bigger balance at the end of the month than if you compute it once at the end of the month. What you need here is nominal rate that's lower than 5% per month that will give you an effective rate of 5%." Ooops, so back to the books.
In the current problem, it turns out there are two domains: parenting of course, and to a lesser extent, finance. I had assumed that I knew enough about the latter, but clearly I was wrong. So, I dropped the design and hit the books until I understood enough about the second domain to proceed.
This problem might have emerged sooner had I not left out an essential second step to the design process: After you've become familiar with the problem domain (step 1) but before you start modeling (step 3), you must interview your users to discover what they need. I didn't think I need to do that since I was already a domain expert—a parent. I was wrong. Had I interviewed a second domain expert, someone not as involved as myself in the actual design (my wife for example), I probably would have gotten this interest stuff right in the first place.
There are lots of issues here, but the most important is what I call the "the bathroom effect." This names stems from a (unpublished) article that I wrote for Dr. Dobb's Journal a few years ago that started out: "Suppose we built houses the same way we built software." (We'd all be living in a poorly built version of the Winchester Mystery House). Anyway, towards the end of the article, the buyer finally gets to see the house for the first time (after it's entirely built). Looking around with a puzzled look, the buyer says "Where are the bathrooms?"
"Bathrooms?" says the contractor, "there weren't any bathrooms in the spec. It will cost a fortune to add them now, we'll have to jack-hammer up concrete, rip open walls, why don't we just patch on an outhouse in the back yard."
"Waddya mean 'it wasn't in the spec'?" stammers the buyer, "who'd be dumb enough to build a house without bathrooms."
And that's often the problem with software, it often doesn't occur to a user to mention something, precisely because it's so fundamental to the problem. It's not that the users are "hiding things from me," as many (bad) programmers constantly say. It's, rather, that the designer doesn't know enough about the problem domain to ask the right questions.
When conducting these interviews, listen, don't interpret. It's very important not only to capture everything that comes out in the interview (someone who can take shorthand is a real asset) but also to record the domain expert's words exactly. I've sat in many meetings where the users went on for hours without anybody writing anything down. Later on, when the user wasn't there, nobody could accurately remember what had been discussed. There's also an unfortunate tendency on the part of programmers not to pay attention to what the user says—to try to distort the user's description of what a problem is into a description of what the programmer would like the problem to be. Programmers like restate things, shuffle around words, translate statements out of the problem domain into a more-familiar vocabulary, and otherwise distort or modify what they hear. More often than not, what gets captured is the programmer's flawed misunderstanding of the problem, not the problem that the domain expert actually describes.
Finally, bear in mind that most users have a long history of trying to deal with arrogant computer geeks who think that they know more about any problem then the user. (After getting an incomprehensible set of directions, the city slicker says to the farmer: "You're not very smart, are you?" The farmer replies "That may be so, but I'm not lost.") The problem is that many users just give up after a while. Why bother to communicate if the programmer doesn't listen? You'll have to break down these sorts of barriers.
The main issue with respect to problem statements in general is whether this level of detail belongs in it at all. Normally, the problem statement itself wouldn't bother to define technical terms in the actual problem domain. You'd just consult a textbook or dictionary for that purpose. Here, however, the answer is "yes" because the distinction between nominal and effective interest is not part of the actual problem domain (which is parenting). Our domain experts are parents, not bankers or accountants. We are not developing a system for use by a bank or making any attempt to model the way that a real bank works inside. This is a piece of kid's software, not a turn-key banking system, so can't assume knowledge of how interest is computed on the part of our domain experts. Interest computation is an important part of defining the problem, however, so it indeed belongs in the problem statement.
It's essential to keep the problem statement focused on the problem at hand. We don't want to solve the general problem of "banking" in a piece of kids software. On the other hand, we don't want to leave out an essential detail either. If the average reader (who is assumed to be a domain expert) needs some piece of information to make sense of the problem statement, then it belongs. If the information is an essential part of the domain, we wouldn't add it. In the current case, if I really was writing a turn-key banking system, I certainly wouldn't bother to define "effective interest" because that's something that I'd expect my domain expert to know. (By the same token, the designers must know enough about the problem domain to understand these basic terms of art as well. You can't design an accounting application unless you know something about accounting—at least at the level of an "intelligent layman.")
So, I dug out an old finance-for-the-complete-idiot book, looked up "nominal" interest, and modified the definition of "interest" as follows:
|
Now things are starting to look more reasonable, though it turns out that we're still
not done, but that's the topic of next month's column.
Verifying The Analysis
Getting it right
The next step (after capturing the problem definition on paper) is to make sure that you've "got it right." There are several activities that you can use for this purpose (mock ups, UI prototypes, etc.), and I'll go through them this and next month. Bear in mind as you read that it's the nature of a magazine article to be sequential, but in the real world many of these activities go on in parallel. For example, I'll be refining a mock up as I create a UI; I'll be using information discovered by use-case analysis to improve the UI, and as I work on the UI, I'll identify flaws in my use-case analysis. By the same token, as I start working on my mock up, I'll inevitably find flaws in my original problem statement and will have to go back and fix them. Design is not an orderly step-by-step process where you can neatly tie up all the loose ends of one activity before moving on to the next. Moreover, you're constantly revisiting work that you thought was finished, updating it with information you discover in the work you're doing right now.
This constant revision is just part of the process, and it's essential that you do it. It's all too easy for a design document to become "stale" because it's not updated in this way, and your design documents will be essential documentation for a maintenance programmer who will see the code for the first time a year from now. Though I think that code can be self documenting if written carefully—with well chosen variable and method names, good structure, and so forth—I disagree with Kent Beck and the "Extreme Programming" crowd when they claim that it's hopeless to keep design documents in synch with the actual code, so you shouldn't bother to try.
Since the design is so fluid, my preference is to keep as much of it as possible
(literally) visible. Stravinsky, when he wrote the Rite of Spring, put the entire
score up on the walls of his apartment so he could look at the piece as a whole.
I, personally, think that this is a good idea with software as well.
For example, rather than using OO CASE tools,
which hide the design documents inside the computer where you can't see them, I prefer
to use vast quantities of white board, and leave as much as possible on the
white board for as long as possible. 50-yard roles of white butcher paper are also
a good medium for this purpose.
Only when things get relatively stable will I consider moving the design into a CASE tool,
and I won't use any CASE tool that won't let me easily print out the entire design so that
I can tape it back up on the wall.
Mock-up a Solution
One of the first steps in the direction of "getting it right" is to make sure that this problem is worth solving. I usually answer that question with a mock up.
There is an important difference between a "prototype" and a "mockup." Using an aviation analogy, the "prototype" Boeing 777 was a fully-functional airplane. Other than the fact that it was pretty beat up by the time that the design process was over, it was exactly the airplane that Boeing shipped. A prototype is really a partially built program, not a throwaway. Like the 777, you use the prototype program as a test bed for design ideas. If the idea works, though, you keep it in the prototype. That is, the prototype is a partially built version of (usually, part of) the final program. Prototypes have to be carefully designed and constructed. This is the finished program you're working on. This sort of development—the gradual refinement of a prototype until you arrive at a finished product—is often called "incremental refinement."
In the current situation, I didn't want a prototype, though. I wanted a mockup. I wanted to see if the whole idea of a bank for kids made sense; I didn't want to build the thing. A mockup, then, is something you pungle together out of duct tape, chewing gum, paper clips, cardboard, and paint just to test a concept that you don't necessarily want to implement. Boeing might have mocked up the 777 cockpit just to see if all the switches could be reached from the pilot's seat. They could do that using plywood and a seat out of an existing airplane. The prototype cockpit, on the other hand, would be full size, completely wired, with real instruments, seats, and switches in it. It might be hooked up to a computer flight simulator rather than an airplane, but you could put it into an airplane if you wanted to.
Another way that you can look at a prototype is that it provides the answers for important questions that come up a design time. For example, often, the only way to answer the question "do we have enough bandwidth to do X" is to prototype the part of the program that does "X" (or at least the network-related parts of the program). If you don't create the real code (that is, if you mock up the problem in an artificial way), you haven't actually answered the question. The real version might not behave like the mock up.
So, I implemented a mock up for the Bank of Allen in Excel.
In the mock up, the bank was a simple spread sheet, one row per day.
You could make deposits by entering them in the correct cell of the
spread sheet, and see the current balance and accumulated interest
in another cell. This would be a miserable UI for the real program,
of course, but this is just a mock up.
Submit the mockup to a real user
I then tried out the concept on my then-seven-year-old son, Philip, using my mock up. The results of the experiment were stunningly successful. First of all, Philip figured out the notion of compound interest on his own.
I said: "So, at the end of the month, you get back your original dollar, plus another nickel that the bank pays you just to keep your money."He clearly liked the idea of making money without working for it. The proof of the concept was that during the months-long trial using the Excel mock up, Philip didn't withdraw a penny.
He said: "So the next month I get even more than a nickel because I now have more money in the bank?"
Cool.
Two concrete improvements did emerge from the mock up. It turned out that Philip was constantly asking how much money he had in his account. The one concrete effect of the mock-up process was to modify the Problem Statement as follows to reflect this new requirement:
It's important that the kids see how interest accumulates on a daily basis; monthly interest postings are not adequate. Consequently, the bank compounds interest daily, and posts daily. The passbook shows this daily posting, even if there is no other activity on that day. This way the kid can see interest accumulating, even though no deposits have been made. The total interest earned over the life of the account is also prominently displayed in the passbook. |
The second issue didn't appear until the mock up was in use for some time. Philip did eventually make a withdrawal to buy a Pokemon card that he had his eye on, but he was short a dollar or so. I offered to loan him the money "just like a bank." That is, I would charge him twice as much interest as he made by saving. This extra loss was enough to discourage him from making the withdrawal (so my primary goal of teaching him how to save was indeed working), but I did think that the ability to make a loan at some point in the future would be handy. Consequently, a second addition to the problem statement is in order:
Kids should be able to borrow money from the bank, but this process should, again, mimic a real bank. The interest rate on loans must be high enough to make the point that borrowing is expensive (say, twice the savings rate), and the bank should impose a requirement for a regular payment over a fixed, relatively short, payback period (a few months at the outside). The kid can pay back the loan using automatic, periodic, deductions from savings. Again, as the point of the exercise is to teach money management, the bank must be able to show the kid a loan statement that makes it abundantly clear how much the loan costs. Moreover, the passbook should highlight the automatic deductions, show both the principle reduction and interest paid. The bank charges a penalty, set by the parent, for late payments. |
Gold-plating
My main reservation with this last addition is that Philip did not actually make a loan, so I'm not sure whether or not I actually need to implement loans. There's no point in implementing features that won't be used. In fact, that's a big problem with many existing programs: they're chock full of features that might need to be there, but which aren't actually used by anyone. This sort of "gold plating" does nothing but make the program more expensive by virtually every measure: it costs more to build, it takes more time to build, it costs more to the user because the company has to recoup the construction costs. The golden rule is:
A program should implement exactly those capabilities that are actually used by the end user; no more, no less.The overall design, however, should be sufficiently flexible that new features can be added easily at some later date.
With respect to the current problem, I decide to leave out loans for
the time being in order to get the program to market faster. I'll
try to come up with a design that will easily let me add them in
at a later date, however.
Users, Marketing, and Sales
One final point to bring up with respect to the mock up. Jacob Nielsen once wrote (unfortunately, I can't remember exactly where), that showing your prototype to two users is twice as useful than showing it to one, but showing it to three users is only about 2.5 times as useful as showing it to one. Running it past more than three users is a waste of time.
Having a real end user actually be a part of the design team is essential, not just to help in the product definition, but to provide constant feedback throughout the design and implementation process. Having two users is even better, but the second one can be on call for doing things like checking out live prototypes and mock ups. In fact, it's probably better if the second user isn't intimately familiar with the entire design process so that his or her input will be as fresh as possible.
If a real end user isn't available, someone from your marketing (not your sales) department—a user surrogate, if you will—can be used. This distinction—between marketing and sales—is important. The main purpose of a good marketing department is research. Marketing is the process of trying to figure out what program will be truly useful to real people in the real world who are doing real work. They accomplish this work with surveys, one-to-one conversations, and so forth. The notions of "business development" and marketing go hand in hand. In a very real sense, the formal problem statement is a marketing document, but it must be created in collaboration between the marketing and technical side to assure that the program can actually be built in a timely fashion. The classic trade off between features and time-to-market is a marketing decision.
The job of the sales department, on the other hand is to sell an existing product. The sales department has absolutely no business specifying features, and should never be permitted to communicate directly with the technical side. Sales should suggest a new feature to marketing, which would then verify that the feature is actually valuable to the user community. If the feature was indeed valuable, the marketing side would then collaborate with the technical side to add the feature to the design, and eventually to the program. Programmers, by the way, must add features that are specified by marketing, no matter how hard it is to add the feature. It's marketing's job to come up with the minimum feature set required for the product to be dominant in the market. If you don't have those features, the product won't be successful. A programmer cannot be permitted to sabotage the success of the company simply because adding a feature is inconvenient.
Things go horribly wrong—and many of us have experienced this process—when
the design is driven by sales rather than marketing. One customer calls
in with a request, which is turned by the sales person into a
OH-MY-GAWD-WE-HAVE-TO-HAVE-THIS-YESTERDAY!!! requirement. Some hapless programmer is then
pulled off useful work and forced to work on this new feature. Three days later, the
same thing happens again, and the push to add the first feature
is abandoned and replaced by some new GOT-TO-HAVE-IT-NOW!!!!! feature.
The end result is that nothing ever gets finished, and that, if by some miracle, a functioning
program is produced, the program probably won't do anything useful.
It's just plain wrong to add a feature or modify a design solely because on customer
has asked for it; otherwise, you run the risk of turning your software company into a
custom-software house with one customer.
The real question is: Is this feature useful to the broader
user community? And that's a marketing question.
So that's it for mock ups
So much for the mock up. Next month we'll start with use-case analysis and UI
design.
Resources
Kent Beck's "extreme programming" is described in Extreme Programming: Embrace Change (Reading: Addison Wesley, 2000; ISBN 0-201-61641-6).
To see the real difference between a mockup and a prototype, check out PBS's documentary on the building of the Boeing 777: 21st Century Jet: The Building of the 777.
Jacob Nielsen's thoughts on prototyping in the context of usability are described in:
Usability Engineering
(San Francisco: Morgan Kaufmann Publishers, 1993; ISBN 0-12-518406-9).
Introducing Use Cases
The "Problem Statement" looks pretty good at this point. I've probably forgotten something critical, but there's no point in sitting around hoping that these missing pieces with spring from my head, fully armed, like Athena from the head of Zeus. By moving on and looking at the same problem in a different way, these missing pieces will become evident. The next step, then, is to look at the problem again, but this time from the perspective of dynamic (i.e. runtime) behavior. In a sense, the Problem Statement is a static definition of the problem—it describes the problem that the user has to solve, but that's it. Eventually, I'll formalize this view of the system into something called a static model.
The dynamic definition of the problem focuses, not on what has to be done, but on how you do it. That is, rather than looking at the problem itself, we'll look at the things the users have to do to solve the problem. The main tool we'll use to structure our thinking on that dynamic behavior is use-case analysis. Dynamic behavior can also be formalized into something called the dynamic model, but before we can do that, we have to figure out what the dynamic behavior is. We'll do this using a technique called use-case analysis.
First of all, a definition:
A use case is a single task, performed by the end user of a system, that has some useful outcome.
The definition of "end user" and "outcome" can vary—an end user might be an automated subsystem, for example, and the nature of the outcome can vary radically from use case to use case. Sometimes the outcome is a physical product like a report, sometimes is an organizational goal, like hiring an employee, but there's always an outcome that has a perceived (by the user) value.
You can think of a use case in terms of user intent.
If a user walks up to our system with the intent of doing something,
what is that "something?"
Logging on is not a full-blown use case, for example, since nobody walks up to the
system with the intent of doing nothing but logging on. You're logging
on in order to accomplish some other larger end, to perform some useful task,
and the use case is the definition of that larger task.
Presenting a Use Case
As is often the case in software, an organized semiformal presentation of the use cases helps you get organized. The formal presentation typically involves several pieces, listed in Table 1. (I'll explain what each section contains momentarily.) It's probably best to look at Table 1 as a checklist rather than a fill-in-the-blanks form. Not all sections are relevant in every use-case definition, and the sections can be combined (or omitted) in a real working document.
Moreover, though the categories in Table 1 must all be addressed, they don't need to be addressed in the order specified in the table. Often, it's best to start with the scenarios, develop these into a formal workflow definition, and then fill in the other details. The ordering in Table 1 is really for the convenience of the implementer, not the creator, of the use case.
We designers have several major goals in creating use cases:
- Developing an increased understanding of the problem.
- Communicating with the end users to make sure we're really solving their problems.
- Organizing the dynamic behavior of design (and the resulting program) to reflect the actual business model in the user's mind. In other words, assuring that the program actually does something useful for a real user.
- Providing a roadmap and organizational framework for the actual development process. (More on this in a few months when we start talking about implementation.)
|
Use-case definition is a collaborative process. Many of these components are specified by the business-side (typically marketing) organization, and others are filled in or expanded by the technical-side organization. The user-interface design is also an important component of use-case analysis. A UI mock up (not a prototype) provides a lot of useful feedback about whether we've captured the use cases correctly. I'll come back to use-case-based UI design next month.
For now, lets' expand on Table 1 and spell out the sections of the
document in detail:
Name
All use cases should be named. Constantine recommends using a gerund followed by a direct object (for example: "withdrawing funds" or "examining the passbook"). This convention encourages the use-case name to succinctly identify the operation being performed and the object (or subsystem) that's affected by the operation. I think that this recommendation is fine, as far as it goes, but there's no particular benefit to rigidly following a formula if you end up omitting important information as a consequence. For example, "customer withdrawing funds from checking account" might be a different use case than "bank manager withdrawing funds from customer's checking account." A simple "withdrawing funds" is not a sufficiently descriptive name.
Names should always be user-centric, not system-centric. For example, "making a deposit" (user-centric) versus "accepting a deposit (system-centric)." Name from the perspective of the user, not the system.
A name, regardless of format, is critical—you must be able
to identify the use case unambiguously to be able to talk about
it effectively. I also typically assign some sort of administrative
identity to every use case so that
it can be referenced easily from other documents.
I usually prefer combining a very general description with
a hierarchical numbering scheme
(e.g. {i "withdrawal: 1.1}).
Customer (Specifier) Contact Information
One of the more unpleasant experiences I've had was working with a Marketing guy who put together use cases based on a fantasy of what the customer wanted, rather than asking the customer. It unfortunately didn't occur to me that his (quite well done) use cases were created from whole cloth. The result was a lot of time and money wasted specifying a product that was of no interest to the customer whatever.
This sort of problem often arises when the focus is on sales rather than marketing. Too often in a sales-driven organization, a product is specified in the hopes that someone will want to buy it, and then the sales force goes out and tries to sell it to unknown buyers. There may be no such buyers, in which case the company fails after burning up several million dollars of the investor's money. A (I think better) marketing approach starts out with research that determines what a select group of customers actually wants. You can then build the product with the real needs of real customers in mind. This approach lowers the risk of new-product development considerably, and use cases are a natural byproduct of that research.
Having been burned once (that wasted effort defining a useless product
contributed not insignificantly to the failure of the company), I now
try to assure that the use case is based on reality by requiring contact
information for a real (or potential) customer who is actually specifying
what the program will do. It's the designer's job to capture this
specification in a set of use cases, not to make the specification up based
on probably erroneous assumptions about what the customer wants.
The manager should contact the customer occasionally to find out how things
are going.
Description
Describe what the use case is accomplishing. What will the user be doing while "withdrawing funds" or "examining a passbook," for example. Go into detail, but don't describe how the user might use a computer program.
For example, a bank customer might make a withdrawal by filling out a withdrawal slip and presenting the slip to the teller. The teller then takes the withdrawal slip to a bank officer for approval. The bank officer checks the account balance and issues an approval, etc. Note that nowhere in this discussion have I talked about computer programs, menus, dialog boxes, etc. These sorts of implementation details are irrelevant at this level. (Though, of course, you'll need well-defined implementation details before you can code, we're not there yet).
I have a particular pet peeve
about an analysis-level
document that mentions "the system." It might be your
problem to create a "system" of some sort, but it's certainly not
your user's problem, and it's the user that's important, here.
Desired Outcome
By definition, a use case should have a useful outcome. Some sort of
work that has value must be performed. Describe the outcome here.
The outcome might be a report (in which case you should include
an example of what the report will look like), an event or
condition (an employee will now receive health benefits), or the
like, but there must be a useful outcome.
User Goals
What are the real goals of the user with respect to the use case? Note that goals are not the same thing as the use-case description. If the "Desired Outcome" section describes what the user hopes to accomplish, the "Goals" section describes why the user is doing it.
Knowing the user goals can influence the direction of a use case
in radical ways. To borrow and example from Alan Cooper, lets say that
we are charged with creating a meeting-scheduler program.
A tempting use case is "scheduling a meeting." Visions of calendars
and appointment books immediately pop into your mind. But beware!
That way lies Microsoft Outlook—a bloated hard-to-use program
that does virtually nothing useful for anybody
(now tell us what you really think Allen).
So, how do we avoid the Outlookification of our system? By
considering goals. What is everybody's goal with respect to a
meeting? I guarantee that we all have the same goal: not to go at all.
Lacking that, our goal is to get out as quickly as possible, and to
make the meeting as productive as possible. The only way to achieve
that goal is to have an agenda. Therefor, the first step in the
"scheduling a meeting" use case is the subcase "creating an agenda."
(More about subcases in a moment.)
The actual deciding on a date and time turns out to be secondary.
Participants/Roles
The participants in a use case are not physical users, but are rather the roles that a physical user might have with respect to a system. For example, if we're doing a time-sheet authorization system, two roles come to mind immediately: Employees (who fill out time sheets) and Managers (who authorize them). The fact that the same physical person might take on both roles at some juncture is irrelevant, there are two logical participants: the employee and the manager.
I've deliberately avoided the UML characterization of these roles as "actors." To my mind, the physical user is an actor who takes on several roles with respect to the system. The actors are often outside the system, and are irrelevant. What's important is the roles that those actors take on. (I'm not alone in feeling that "actor" is a bad choice of terminology; see Resources.)
There is one important exception to the actors-are-external
rule. Consider the issues surrounding access control. You are
authenticating the actor to operate within the program in a given
role. Consequently, the actor has a presence in the program, and
a mapping of actors to roles is central to the way that the
program works.
CRC Cards
For each role, we need to establish two critical pieces
of information:
- The responsibilities of actor when in this role. For example, bank tellers get deposit and withdrawal requests from customers, and get approvals for withdrawals from bank officers.
- The actor's collaborators—the roles with which communication is necessary. For example, a bank teller collaborates with both the customer and the bank officer, but the officer never collaborates directly with the customer.
Dependencies
Dependency relationships sometimes don't exist, but that's unusual when a program is complex enough to have more than one use case. Often the dependency relationships are not immediately apparent, but are discovered as the use-case model and associated user interface evolve.
Typical dependency relationships include one or more of the following:
- subset/combines.
A subset use case (which I call a subcase)
typically appears when you start analyzing
the top-level cases and discover that a complex task can
can accomplished by performing several smaller, but stand alone,
tasks. Each of these stand-alone tasks are a subset of the
main use case. Whether you use "subset" or "combines"
is really just a matter of where you start. If you start
with smaller use cases and realize that you can combine them
together into a larger one, then use "combines;" if you start
with the larger case and decompose it, use "subset."
For example, though identifying yourself (logging on) is typically not a use case in its own right (you wouldn't approach the system with the end goal of identifying yourself [and then shut off the machine and go home]), it might be a subcase of other use cases. More to the point, the identification process might be the same in all use cases that required identification. It's useful to create an "identifying yourself" subcase and spec. it out as if it were a stand-alone use case, and then incorporate it by reference into the main use cases.
- uses/is-used-by (includes).
This one is very similar to a subcase relationship; don't waste a lot
of time worrying about whether a "uses" or "subcase" relationship
is better, since the two relationships are treated much the same way
when using the use-case document. The main distinction between "subset"
and "uses" is that a "uses" relationship applies when
a use case is a subcase that is also a stand-alone use case.
(It defines a stand-alone operation that has a useful outcome.)
A subset-style relationship is sometimes used to distinguish
a subcase that is used by only one other top-level use case,
while a "uses" relationship might characterise a subcase that is used
all over the place.
- precedes/follows.
Establishes a workflow between use cases.
For example, "registering a customer" must precede
"specifying an order" or "browsing the catalog."
- requires.
Precedes/follows relationships indicate sequence, but not
dependency. That is, "registering a customer" is required
by the "buying items in shopping cart" use case, but
it simply precedes the "browsing the catalog" use case—it's
not a requirement.
- extends/is-specialization-of.
If use-case B extends use-case A (that is, adds subtasks,
operations,etc.), then B is a specialization of A. (Typically
the extra tasks were needed in order to satisfy some
special requirement that doesn't occur in the normal use
case). For example, "identifying a manager" might be
a specialization of "identifying an employee" because
the manager might have to be authenticated to a higher
security standard than a normal employee.
(This specialization relationship will be called
derivation by programmer types, who would say that
B "derives from" A to indicate that B is a specialization of A.)
- resembles.
Often, you'll notice that two use cases appear to be similar to
each other, though there are minor differences in workflow.
Resembles relationships are indicating that you want to
look closely at similar use cases, trying to find commonality
that can be factor out into "subset" cases or equivalent.
- equivalent. Two use cases can appear to be different from the perspective of the user, but may end up being implemented identically. (In the Bank-of-Allen, deposits and withdrawals may well fall into this category.) It's nonetheless useful to maintain a logical distinction between equivalent use cases. It's irrelevant to the user whether or not the underlying code is the same—deposits and withdrawals are different logical operations. In any event, equivalent use cases have a way of diverging over the course of a design.
I've found that diagramming these dependency relationships using
a UML static-model diagram is quite useful. (On the other hand,
UML's official use-case notation is singularly worthless.) Constantine
and Lockwood have proposed a notation for diagramming use-case relationships,
but I prefer to use standard UML, introducing stereotypes when no
existing notation convention can be pressed into service.
I'll give you a concrete example later on
(in the context of the Bank-of-Allen project).
Preconditions
What assumptions are you making about the state of the world when
the use case begins? For example, customers must have an account with the
bank before they can withdraw money. As a consequence, the
"customer opening an account" use case must have been performed before
the "customer withdrawing money" use case can be performed. That's a precondition.
Inputs
Use cases can require inputs. For example:
- Documents used to do the work. A course catalog, for example, is necessary to register for classes. Specify where the documents come from. (What are their origins?) Was the document an output from another use case?
- Knowledge required by the actors to perform their role.
- Skill required by the actors to perform their role.
Note that the information gleaned while executing a use case
is not an input to the use case itself, it's an output.
Scenarios
Scenarios are small narrative descriptions of someone working through the use case. Use a fly-on-the-wall approach: describe what happens as if you're a fly on the wall observing the events transpire.
As is the case with the Description, I try to keep the scenarios as abstract as possible (talking about how a bank, not a computer program that simulates a bank, is used). "Philip needs to make a withdrawal to buy groceries. He digs out his passbook from under the 3-foot pile of dirty socks in the top drawer of his dresser, and finds that his balance is big enough to cover what he needs, and he heads off to the bank..."
Some programmer-types dismiss the scenarios as worthless fluff, but I've found them useful. The most important use is in clarifying your own thinking. Often, when working through a scenario, I'll discover use cases that I have thought of, or I'll discover workflow issues that were not apparent. For example, a couple of questions naturally arise in the previous make-a-withdrawal fragment. (What if he can't find the passbook?)
For example, consider a use case that might have several relevant scenarios. In a recent OO-Design Workshop that I conducted, we chose the class-registration system for Vanderbilt University as a sample project. There's only one high-level use case, here: "Registering for Classes." Within this use case, several scenarios come to mind, however:
- I sit down, specify up for all my classes, get into them, and I'm happy. This sort of scenario—in which everything works without a hitch—is called (at least by me) the "happy path" scenario.
- I sign up for my classes, but one of them is full so I'm placed on a waiting list. Later on, a space becomes available in the class, I'm enrolled automatically, and am notified that I got into the class.
- Same as above, but the class is required to graduate—I must get into it.
- Etc.
Note that some scenarios are failure scenarios, but it's a mistake to think of the set of scenarios as containing a single happy-path scenario and a large number of failure scenarios. In the class-registration, example, one real failure scenario is that you have to get into a class to graduate, but you can't get into the class.
In fact, in most properly done use cases, there are not failure modes! This astonishing statement is not as shocking as it might, at first, appear. Most computer programs use error messages as a way to mask programmer laziness. The vast majority of "errors" could actually be handled just fine by the program itself; the error message is printed primarily because the programmers who were too lazy to figure out how to handle the error, so the pushed the work onto you, the user. Taking the class-is-full scenario. A lazy designer would say "Oh well, the class you want is full. That's just too bad. Nothing I can do about it" and classify this case as a failure scenario. A competent designer would work out a solution such as a waiting-list strategy. It's your job as a designer to solve the user's problems, not to push the problem back at the user. Alan Cooper goes so far as to say that well-written programs shouldn't print error messages at all. I'm not sure whether that goal is possible, but I'll bet you could eliminate 90% of the error messages from most programs and end up with a more usable system as a consequence.
Also, for you programmer types, note that serious fatal errors—the sorts of things that would cause exceptions to be thrown—don't appear in the use cases at all! These conditions represent the failure modes of the program—they are implementation related and have nothing to do with the problem domain, so don't belong in a use-case analysis. Remember, we are defining the problem to solve from the perspective of the user. We are not designing a computer program, yet. (That will come later, after we fully understand the problem.) An exception-toss error condition is really an implementation requirement (see below) and the should be listed in the Requirements or Implementation-Notes sections.
Don't take the foregoing as an excuse not to think about failure conditions. Your goal is to think of every possible failure condition, and then make sure that every failure is handled gracefully every time it comes up. It can't hurt to make a working document on which you list all failure modes, and then use that list as a checklist when you review the use cases to make sure that they're all covered.
As a final note, the sales staff will find the scenarios really useful in
putting together presentations. It's always good to sell the
product that you're actually building.
Workflow
Often the use-case description is sufficient to describe the
flow of work through a simple use case ("do A, then do B, then do C").
Sometimes the workflow is so complex that it would be inappropriate
to attempt to describe all of it in the Description section, and
sometimes a diagram (like a UML workflow diagram, which I'll
discuss eventually) is needed to
unambiguously define the workflow. That sort of information goes
here.
Postconditions
It is often the case that a use case changes the state of the world
(the account balance is now lower) rather than
generating a physical product. Also, some use cases need to
be followed by others to complete an entire task. This sort
of information goes in the Postconditions section. That is,
a postcondition is something that you can check after the
use case completes in order to determine the success or
failure of the use case. An example postcondition:
the new balance is the old balance, less the amount withdrawn.
Outputs
There are two broad catagories of outputs:
- Documents are created during the course of the use case. The output of our class-registration system is a schedule of classes, for example. Also list where the documents go. Who will receive the document? How do you get it to them? (This last might be a use case in its own right.)
- Knowledge gained while executing the use case. What do the actors know now that they didn't know before they performed the use case?
Business Rules
Business rules are policies that the business establishes that
might effect the outcome of the use case. For example, "You may
not withdraw more than $20 dollars within a 7-day period."
It's not a good idea to clutter up the use-case description
with these rules, but they have to be specified to make the
document accurate enough to be usable.
I've found that it's best to specify
These rules in a separate document and then reference the
individual relevant rules here in the "Business Rules" section.
Requirements
Requirements at typically customer-specified behavioral constraints on the implementation of a system. ("You must support 10,000 transactions per minute.") They are, again, best specified in a separate document and referenced here.
Note that some things that are called "requirements" actually aren't. UI design is often specified as a "requirement," but the real requirement is typically not how the program looks, but what it does. If the real users could care less whether the program uses kidney-shaped nested mauve buttons, then it's certainly not a "requirement" to use kidney-shaped nested mauve buttons, no matter how much you like kidney-shaped nested mauve buttons. (On the other hand, if the users do care, then it's indeed a requirement, no matter how silly it might seem to you. Live with it.)
I once had a client who was fond of the phrase "The users demand some feature." My response was "Which users? Give me their names so that I can call them up and discuss it." Since no such users actually existed, it was easy to discount these demands. This is not to say that designers don't occasionally think of useful features, but unless a real user is enthusiastic about your innovations, then they aren't real. It's really easy to browbeat your user community to accept some gawdawful innovation that will do nothing but annoy them for the life of the program. Resist the temptation.
A good test for whether or not a requirement is valid is to reject any so-called requirement that specifies up front something that is a natural product of the design process (UI look and feel, program organization, etc.). Such "requirements" are just bad knee-jerk design. Expunge this junk from the requirements document.
If you have a well-trained business-development team, these sorts of "requirements" won't be in the document to begin with.
Finally, note that it's impossible for an OO designer to
work from a list of "features." Feature lists tend to be
long, disorganized collections of poorly-thought-out
ideas that some customer suggested to a salesperson off the
top of their heads. The salesperson then translates that
suggestion into "OH-MY-GAWD-WE-HAVE-TO-HAVE-THIS-NOW!!!," and
away we go. At best, they suggest avenues of
research, but by themselves are of dubious value. What you're
interested in is why the feature was suggested. How would
this particular feature make the user's job easier? What is the
user trying to accomplish? Do any of your other
customers need to accomplish the same thing?
Is there some better way to accomplish the goal?
Most importantly, is the task that the user is doing really
a use case that didn't occur to us?
Implementation Notes
Though it's our goal to keep the use-case document as
grounded in the problem domain as possible, it's natural for
implementation details to occur to you as you work through
the scenarios and workflow. You want to capture this information
when it pops into your head, so this section provides a place
to jot down implementation notes. These notes aren't bolted
in concrete—they aren't an implementation specification;
rather, they're details that will affect implementation
and are relevant to the current use case. They will guide, but not
control the implementation-level design.
Summing up
So that's the organization of a use-case. Next month I'll show you how
to apply the theory by developing a few use cases for the Bank-of-Allen
project. Future articles will also show how to use the use cases for
UI design, and how to build a formal dynamic model from them.
Resources
Ivar Jacobson, Object-Oriented Software Engineering : A Use Case Driven Approach (Reading: Addison-Wesley, 1994; ISBN: 0201544350). This book is one of the first treatments of use cases. Though Jacobson is a pioneer in this field, I do have some arguments with him about things like use-case granularity. I've listed the book because it's seminal, but it's a bit abstract for my tastes.
Larry Constantine and Lucy Lockwood, Software for Use (Reading: Addison-Wesley, 1999; ISBN: 0201924781). This book describes a use-case-based UI-design methodology called Usage-Centered Design. The approach is one of the best formal UI-design methodologies going, and the first quarter of the book is a good discussion of use-case gathering.
Larry Constantine and Lucy Lockwood, Structure and Style in Use Cases for User Interface (http://www.foruse.com/Files/Papers/structurestyle2.pdf) This paper both summarizes and expands on the design approach discussed in Constantine and Lockwood's book. It's a good capsule introduction to the subject.
Russell C. Bjork,
An Example of Object-Oriented Design: An ATM Simulation
(http://www.math-cs.gordon.edu/local/courses/cs320/ATM_Example)
These are wonderful course notes for a class that Dr. Bjork is teaching
at Gordon College. Though I have some criticism of some of the documents,
Bjork does present a complete set of the design artifacts (including
use cases) that arise from the OO-design process.
Creating Use Cases
Let's start with a reprise of the definition of use case from last month:
A use case is a single task, performed by the end user of a system, that has some useful outcome.Looking at the Bank-of-Allen problem statement from prior months, a few use cases spring out at me:
- Kid Depositing funds into an Account
- Kid Withdrawing funds from an Account
- Kid or Parent Viewing a Passbook
- Parent Opening an Account
- Parent Changing an Account
- Parent Closing an Account
- Bank Loaning funds to a Kid (defer to version 2)
At this stage, this list is just guess work. I'm sure that I'll discover additional use cases as the process unfolds. Moreover, some of these use cases might turn out to be large enough that they will have to be decomposed into smaller chunks. (In general, by the time we get to an implementation-level design, no use case should take longer than a month to implement. In fact, one-person-month-per-use-case is a good rule-of-thumb metric for rough estimation. Some methodologies—such as Kent Beck's XP—want use cases that are small enough to be implementable in a couple weeks.) Note that the low-level atomic operations, such as computing interest, aren't listed, since they aren't stand-alone use cases. These will almost certainly be subcases, though.
Now that I have something down on paper, I can start designing. Looking at the previous list, I've several thoughts. First, I"m not sure whether "Depositing" and "Withdrawing" are separate use cases. The alternative would be something like "Perform a transaction," where "transaction" was either a deposit or withdrawl operation. Two use cases that turn out to have the same workflow are certainly equivalent, but I don't yet know whether that will be the case. For now, I'll keep both use cases since they appear to be different from the user's perspective, and they have different apparent outcomes. (Deposit increases the balance and Withdrawl decreases it. The "Perform a Transaction" use case modifies the balance.)
Turning my attention to "Viewing a Passbook," I'm not sure that it's a use case at all. There's no particular outcome, and the passbook will most likely be displayed during the course of the other use cases. On consideration, I change this one to "Playing what-if games," which does have an outcome: learning financial planning.
Next, I consider opening, closing, and changing an account. There are certainly distinct outcomes from the user perspective, but again, I can imagine that the workflow would be identical for the "Opening" and "Changing" cases. Certainly the UI would be identical—it's just that various fields would be blank when you opened the account. The trivial differences could be handled with simple conditional branches ("if account is new, then ...") in the workflow.
I decide that Closing an account is a real, though trivial, use case since the UI will be different than the UI for the opening/changing case. I don't want to do what a normal bank does and automatically close an account if the balance is exactly $0.00, because I can easily immagine kids taking their accounts down to a zero balance, and I don't want to redo the setup in that situation.
Finally, I decide to toss the "Loaning funds" use case. It's a good version-2 feature, but I don't need it immediately.
Note that as I make these decisions, I'm imagining implementation details (the UI). I am, after all, designing a computer program, so need to look forward towards implementation. Nonetheless, I'm simultaneously trying to keep my thinking in the problem domain for as long as possible. I'm using an imagined implementation to help understand domain-level issues, but I'm not designing that implementation, and I'm not wedded to it. The UI, then, is a design aid that helps me clarify my thinking about domain-level problems. This is a very different approach than the VB-style approach recommended by Alan Cooper, in which the UI design drives the program-design process. Here, the program will fall from the conceptual model, and the UI is just a convenient tool in developing that conceptual model.
Things like "backing up," "saving," etc., are not use cases because they don't occur in the problem domain. This also tells us something about how the program should work, however. It shouldn't be necessary to explicitly "save" before exiting any program, especially this one. If you make a deposit, you make a deposit. It's just unnatural to require an additional operation like saving for that deposit to be realized. I can garantee that your average 10-year-old won't think about saving before exiting. If you think about it, requiring a "save" operation is the same thing as making "throw away all my work" the default behavior of a program—not a particularly good default, if you ask me. Same for "backing up." Either the program should back up automatically as a side effect of changing the state of an account, or the program must maintain an audit trail that lets you undo the changes. It's rare that any operation that doesn't appear at the domain level should appear in the UI. Possible exceptions might include "Help," but if the UI is sufficiently intuitive, help shouldn't be necessary. You could also argue that the program should notice when you need help by watching your behavior, and offer it to you at that time. Most configuration options are never changed by users, so there's no point in cluttering up the UI with that kind of junk. (Exceptions, of course, being configuration issues that appear in the problem domain, such as currency representation, though even that could be done automatically by detecting the current locale.)
The tentative use-case list now looks like this.
- Kid Depositing funds into an Account
- Kid Withdrawing funds from an Account
- Playing what-if games
- Parent Opening or Changing an Account
- Parent Closing an Account
Specifying a Use Case
The next order of business is to use the categories from last month as a template for formally specifying the use cases. Table 2 summarizes the pieces of (my flavor of) a formal use-case presentation.
|
A few preliminary comments about how the use-case document is built are in order. I've ordered the sections of the template by considering how the template will be used. You'll rarely create the template in the same order that you use it, though. I've presented the use case in the template order, but I was skipping around in the form when I actually put the thing together. I started out with the name and description, then skipped down and worked on the scenarios a bit, then skipped down and added an implementation note, then skipped back up and worked on the scenarios some more. Then, I filled in the Desired Outcome section, and then skipped down and added a postcondition, and around and around we go.
Moreover, in a real-world situation, it's rare that a person would develop an entire use case singlehandedly. Ideally, the business-related components (The use-case name, the description, the scenarios, the user goals, perhaps the desired outcome) would be developed primarily by the Marketing side, with Engineering in a consulting role. The technical items (dependencies, pre- and postconditions, formal workflow analysis, implementation requirements and notes) would come primarily from Engineering, with the marketing organization in a consulting role. Business Rules and Requirements are typically created jointly. It's even better if a real-live customer—an actual user of the product—participates in the process, too.
You'll also work on several design artifacts in parallel. It's natural to uncover hitherto unknown aspects of the problem as you work on the use cases, and you should go back and add these to the problem statement before you forget them. Keeping the various documents that comprise the design in phase with each other is a real problem with a large design. It's a critical thing to do, however. As soon as you discover some flaw in your thinking about a problem, you have to change all the relevant documents immediately. I typically have the problem statement, any relevant use-case descriptions, the UML diagrams, and the code, all in front of me at the same time as I work. It's also important to be able to roll back to previous designs if you go down a wrong path, though I don't know of any automated document-management packages that make rollback truly painless since many types of document—drawings, formatted text, ASCII source code, etc.—comprise the design, and they might all be affected by the change.
Now let's look at the the first use case.
An Example Use Case
- Use-Case Name
- 1.0. Kid Depositing Funds into Account
- Customer (Specifier) Contact Information
- Philip Holub. Available at home, after school on weekdays, and on weekends. DJ Holub. Available at home, after work, and on weekends, as time permits.
- Description
-
A kid (customer) deposits money into his or her account.
Deposits must be authorized by a bank-officer/parent
before they go into effect.
This is the first time that the notion of authorization has popped up in this context, and is an example of how writing a use case can find flaws in the problem statement. During my first pass on this use case, I wrote "parents aren't involved in this use case," but my next thought was "but what prevents the kid from just depositing arbitrary sums of money?" The notion of authorization solves the problem, but introduces a few interesting scenarios, which I'll discuss below.
The original problem statement did cover security issues, but not in a way that's workable. Here's the relevant portion from the original:
There are a few security issues. Like a real bank, kids can't make a deposit or withdrawal by modifying their pass books; they have to ask the bank to do it; the bank processes the transaction and updates the passbook. That is, the kid gives money to the bank, which puts it into the account. The bank takes money out of the account, and dispenses it to the kid. (Practically speaking, this means that only parents can make deposits or withdrawals, but parents should process withdrawal requests when asked or the kids will assume that the bank is a ruse for not letting them get at their own money.)
In retrospect, that business of the bank taking money out of an account and dispensing it doesn't work, because banks don't do that (tellers do, bank officers do, banks do not). So, I now go back and modify the problem statement to bring the notion of parent approval of certain transactions more in line with what I've discovered in the use case. Here's the revised section:
The issue of checks came to me as I was writing—yet another of how the process works. You discover missing pieces of the problem as you look at the problem from different perspectives.There are a few security issues. Only a bank officer (that is, a parent) can change the interest rate, set up a new account (and the initial balance), or close an account. Though, for the most part, kids can use the bank entirely on their own, some transactions (deposits and loans) require parent/bank-officer approval before they can be completed. Transactions like this will be visible to kids, but and will show up in the passbook, but unapproved deposits are not available for withdrawl.
Withdrawls don't require parent approval. A withdrawl request will cause a check to be printed. These checks work like real-world checks. If it's lost, then a stop-payment order can be issued (for a fee). The check can be presented to the bank (a parent) for conversion to cash.
Of course, having made a change to the problem statement, I now need to get domain-expert approval before I can check in the new version. (Since I'm my own domain expert in the current case, that's easy.)
- Desired Outcome
- The account balance gets larger.
- User Goals
-
Kid: To make the account balance as large as possible and to
watch wealth accumulate.
Parent: To make sure that kids don't inflate the account balance with an arbitrary deposits to which they're not entitled.
Note that different users of the system have different goals, and that these goals are often mutually exclusive. Kids want the account balance to be arbitrarily large, but parents want to assure that only real funds, actually available to the kids, are deposited. This sort of goal clash is commonplace, and one of the points of the current exercise is to identify (and address) these clashes.
- Participants/Roles
-
I'll identify the roles using the CRC-card format I discussed last month. This list, again, is developed over time as I work on the scenarios; what you see here is the final form of the list.
Note that some of the participants are automated (the Teller) and others are real people. Also note that some of the participants are passive objects in the system (Passbook). This is one place where a use case that's intended for program development might vary from one that's used for UI development: A UI-style use case would typically be interested only in the roles taken on by the physical users of the system. In OO systems, though, even objects that you think of as passive have responsibilities and operations defined on them. (For example, the passbook might print itself.)
Class Responsibilities Collaborators Kid (bank customer) - Fills out deposit slip.
- Holds the passbook.
Teller (handles the Kid's requests). Parent (bank officer) Authorizes deposits. Teller (requests deposits from). Teller - Solicits deposit slip.
- Gets permission to make deposit from bank officer.
- Updates passbook.
Parent (authorizes transactions for),
Kid (makes requests of).Account ???? ???? Passbook Tracks transaction history. Kid (looks at it),
Teller (updates it).Deposit Slip Identifies the amount of the deposit. Kid (fills it out),
Parent (authorizes it),
Teller (transfers it to Passbook),
Passbook (records it).
I didn't identify the need for a Deposit Slip class until I started flushing out the scenarios, below. You'll see how a Deposit Slip is used when we get down to the Scenarios section. (Remember, the organization I've presented here is more for the convenience of the user of the use case than the creator of the use case.)
Surprisingly, I can't think of anything for objects of the Account class to do in this system. The current balance is held by the passbook, which also keeps a recorded of the transactions on the account. I suspect, then, that the Account and the Passbook are the same thing; All that the account does is assign some identifying information to the transaction record, but if the Kid/customer is holding their passbook, then there's no need to store the identifying information in the account as well, you can just ask kids for their passbooks to find out what accounts they own.
This issue really highlights the difference between a database-style, entity-relationship (ER) worldview and an object-oriented (OO) worldview. Mapping one worldview to the other is called object-relational mapping, and that mapping is rarely straightforward, since you need to reconcile two conflicting organizational strategies. It's rare that a good object model will make a good database schema (or vice versa). In the current example, an ER worldview might consider Customers, Accounts, and Passbooks all to be valid entities. The Customer contains customer-specific identification information and identifies various Accounts that the Customer owns, the Passbook contains transaction histories, and the Account contains account-specific information like current balance. The object model doesn't work that way for reasons I just discussed. Since there's nothing for an Account to do, it's not a legitimate class.
That is, in an OO system, a class shouldn't exist unless there's something for it to do; there must be responsibilities (operations). In fact, a class is defined solely by what it can do—the data that it uses to perform those tasks is an irrelevant implementation detail that should be hidden from the rest of the world. An Account might encapsulate data, but I can't think of any operations that it will perform, thus Account is not a proper class. (See References for more on this way of looking at OO systems.) Put another way, object modelers and entity modelers have fundamentally different worldviews. Object modelers are interested almost exclusively in operations—what what the objects do. The state data that an object must hold to implement those operations is usually irrelevant this early in the design process. An static attribute is of interest to an object modeler only if it can be used to distinguish one class of objects from another. (For example, Employees have salaries, People don't, so the salary attribute serves as a distinguishing characteristic of Employee.) Database entity modelers, however, concern themselves soley with the static attributes—the operations are immaterial to them. The net result is that organizations that are anathema to entity modelers (classes with no state data at all, one-to-one and many-to-many relationships between classes, etc.) appear all over the place in OO systems. The final culture-clash issue surrounds the organization of the static data. In an OO system, for example, the members of a Committee would effectively be contained within the Committee class. That is, the members would be static attributes of the Committee class. In a relational system, it's more likely that a Committee identifier would be an attribute of the member (so that you could join or select on a committee name).
But I digress. The foregoing not withstanding, I'll keep "Account" in the list for the time being in case some operation on an Account surfaces. I suspect that Account will eventually go away, though.
- Dependencies
-
Similar to: 2.0. Kid Withdrawing funds from an Account. (equivalent?) Follows: 4.0. Parent Opening an Account Includes: 6.1. Parent authorizing a single deposit Followed by: 6.0. Parent authorizing prior deposits
This list is tentative. For example, the "Similar to" relationship with use case 2.0 might actually be an "equivalent" relationship.
- Preconditions
- The account must exist.
- Inputs
- The kid has earned some money.
- Scenarios
-
- (Happy path)
Philip has completed his chores for the day, and has decided
to deposit the resulting $2.25 into the Bank of Allen. (If he
did his chores every day, I'd be broke by now.) He enters
the bank, asks the teller for a deposit slip, fills
it out, and returns the deposit slip, along with his passbook,
to the Teller.
The Teller asks for some identification before she accepts the
deposit slip, and then sends the slip to the Bank Officer for
approval. The Bank Officer (a parent) authorizes the
deposit by signing the slip, and sends it back to the teller,
who updates Philip's Passbook to show the transaction.
The Teller then returns the Passbook to Philip so he
can gleefully ponder his growing account balance.
Note that I've carefully used the vocabulary of the Problem Statement (discussed in previous installments of this series) in this scenario description (for example, "passbook," "Teller," etc.). Had I introduced new concepts, here—and that does happen—I'd have to go back and modify the problem statement to introduce the new vocabulary. A significant (and difficult) goal of the designer is to keep all design documents "in phase" with each other. If a change in one document impacts another, then both documents must be changed immediately. For example, I have deliberately not said "The teller makes a journal entry reflecting the deposit transaction," because "journal" is not in the domain vocabulary while "passbook" is in the domain. Whether you call it a "journal" or a "passbook" makes no difference to the design.
Also note that I have not used the phrase "the System." The system doesn't do anything; rather, all work is done by actors who take on well-defined roles. Some of those actors (the Kid) are real people. Other actors (the Teller) are entirely automated. Other actors (The Bank Officer) are partially automated and partially real (some of the tasks responsibilities of bank officer are executed by a parent rather than a computer). It's the role that's important; it's immaterial whether the actor performing that role is or is not automated.
- This scenario differs from the happy path in that no parents are around to authorize the deposit. In this scenario, the money isn't actually added to the account; rather, the deposit is entered into the passbook as "unapproved." Any parent can approve the transaction at some subsequent time. In other words, the deposit is "on hold" until it "clears." The Teller returns the Passbook to the Kid, and the deposit will show up in the Passbook, but the funds cannot be withdrawn from the account until the parent signs the deposit slip.
- In this scenario, the parent deposits funds for the kid.
(as compared to the kid initiating, and the parent
authorizing, the transaction).
By this juncture, I've gotten rather tired of the word "kid," as compared to something a bit less flip. I'm deliberately continuing to use the word kid—rather than child, customer, or some other equivalent term—because it's important that the nomenclature of the entire set of design documents be internally consistent. I'm wishing that I had chosen my terms a bit more carefully, though.
The second scenario actually introduces a new use case, which hadn't occurred to me earlier: "Parent authorizing prior deposits." This is really a stand-alone use case, even though authorization is also an operation in the current use case (Implying a subcase: Parent authorizes a single deposit.)
- (Happy path)
Philip has completed his chores for the day, and has decided
to deposit the resulting $2.25 into the Bank of Allen. (If he
did his chores every day, I'd be broke by now.) He enters
the bank, asks the teller for a deposit slip, fills
it out, and returns the deposit slip, along with his passbook,
to the Teller.
The Teller asks for some identification before she accepts the
deposit slip, and then sends the slip to the Bank Officer for
approval. The Bank Officer (a parent) authorizes the
deposit by signing the slip, and sends it back to the teller,
who updates Philip's Passbook to show the transaction.
The Teller then returns the Passbook to Philip so he
can gleefully ponder his growing account balance.
- Workflow
-
This section is the critical one, so I'll deviate a bit from the format I've been using hitherto and show how the workflow evolves. I start out by modeling the happy path as a simple list:
The Happy-path Scenario:
- Kid requests a Deposit Slip from Teller and fills it out.
- Kid submits the Deposit Slip and Passbook to the Teller.
- Teller verifies the Kid's identity as valid.
- Teller sends the Deposit Slip to Bank Officer for approval.
- Bank Offer returns the Deposit Slip to teller, marked as approved.
- Teller makes an entry in Kid's Passbook showing the deposit.
- Teller returns the Passbook to the Kid.
Though a linear list is sufficient for a simple workflow, it doesn't cut the mustard when the workflow gets complicated. Constantine and Lockwood recommend that you represent nonlinear operations using phrases like "In any order:" followed by a list. You could also use "Simultaneously" followed by a list to represent concurrency. Maybe I'm just a visual kind of guy, but I find these words-only representation of use cases to be confusing. I prefer UML workflow diagrams when the use case is at all complicated. The UML for the simple happy path is shown in Figure 1.
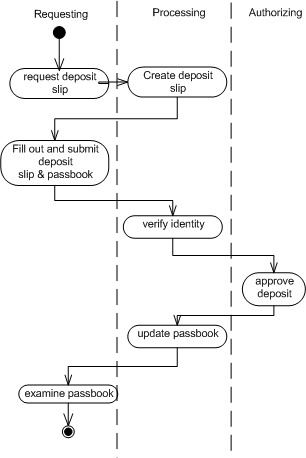
Figure 1. The Happy-Path Workflow Diagram The notation is more-or-less self explanatory. Each box is an activity, flow is indicated by arrows. You start at a solid circle and end at a target. The columns, called swim lanes, identify the class of objects (or the subsystems) that are responsible for performing the activity.
Looking at the diagram, I notice that there is some scope for parallelism. That is, some activities (verifying the kids identity and approving the deposit) could be done in parallel. (You could also say that the order in which these activities are executed is unimportant, provided that they are all executed before moving on to the next step.) Figure 2 shows the modifications required to Figure 1 to reflect this parallelism. The heavy horizontal lines that begin (are at the top of) a set of parallel activities are called forks. The lines at the bottom, at which the activities must synchronize before further work is possible, are called joins.
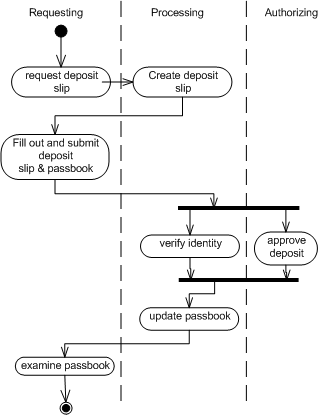
Figure 2. The Happy Path, Modified to Reflect Parallelism Now I go back and look at the other two scenarios, and try to merge them into the happy-path activity diagram. (The modified diagram is in Figure 3.) In general, if it's not possible to merge the scenarios or if the diagram that results from the merge is too ungainly, then the additional scenarios are probably stand-alone use cases, not scenarios of the current use case. The current batch of scenarios merge quite nicely, though.
The parent-makes-deposit-for-kid scenario turns out to be a no brainer once I realize that the workflow is identical to the happy path provided that I permit to parent to masquerade as a kid. That is, a parent's password can be used to log on a kid. I put a comment to this effect in both the Activity Diagram (Figure 3) and the Business-Rules section (below).
The second scenario (where the Parent isn't present) is slightly more difficult because I have to introduce a branch, indicated in Figure 3 as a diamond with one incoming and multiple outgoing arrows. The conditions that control which outgoing path to follow (called guards) are just text labels on the lines. A merge (also indicated with a diamond, but this one with multiple incoming and one outgoing arrow) marks the end of of the conditional behavior. Every branch should have an associated merge.
You could express all the complicated stuff between the fork and the join as follows: In any order, verify the identity of the kid and also mark the deposit as approved if a parent is present, or unapproved if the parent is absent. Update the passbook after both activities (verification and marking) have completed.
Note that the original scenario description specified that the Teller hold unapproved deposits. It became apparant while working with the diagram that it would be a lot easier for the unapproved deposits to be held in the passbook, not by the Teller, so I did that. I went back and modified the scenario description to reflect this change.
- Postconditions
-
- new account balance == old account balance + deposit amount.
Note that the use case encompasses two distinct operations (deposit request and deposit authorization) that don't have to occur at the same time. Nonetheless, this is a single use case with a single outcome. The account balance is always affected, even if some days elapse between the deposit and approval activities.
- Outputs
-
An updated passbook.
This section would be the place where you'd actually show what the output will look like (in the case of a report, for example). I'll defer that until I start work on the UI in a subsequent article.
- Business Rules (domain related)
-
- Deposits must be authorized by a parent before they take effect.
- Interest starts accruing on the day the deposit is made, even if authorization occurs on some subsequent day.
- Unauthorized deposits can remain in the unauthorized state, waiting for a parent signature, indefinitely. They do not become "stale."
- A parent's password will authenticate a kid. That is, parents can log on as kids.
- Requirements (implementation related)
-
- Deposits must be "saved" automatically. There is no "File/Save" menu. An explicit "undo" isn't necessary or desirable. Undo a deposit with a withdrawl.
- The "held" deposits must be displayed when kids view their passbooks. Held deposits will be displayed in gray.
Had I said "highlighted in some way" rather than "displayed in gray," I would be running the risk of writing a worthless specification. By the time we're done, the specification simply can't be ambiguous. Since all decisions have to be made eventually, you may as well get them out of the way now. You can always go back and change things if you make a wrong decision (until the specification is formally approved, of course.)
It seems better to me to make a wrong decision than to make no decision at all. I've seen many so-called specifications that were so mealy mouthed that several hundred distinct programs could be generated from the spec., and all of these programs would be conforming. This sort of ambiguity is worse than useless, since it encourages you to do incorrect work.
In the current case, I suppose, the issue is so trivial that a decision may well be unnecessary. It doesn't matter in the least how the entry is highlighted, as long as it is highlighted. Consequently, this decision could be deferred to the formal UI-design process. If you leave the notion of highlighting indeterminate, the various programmers who are implementing the design will each implement their own notion of highlighting, with the resulting UI being inconsistent and harder to use as a consequence.
- Implementation Notes
-
- There's currently no notion of logging in. Looking at the
scenarios, Philip is not likely to make several transactions
at once; in fact, it's more likely that he'll make a single transaction,
but forget to log off. (This is an observed behavior from my home
testing lab—Philip often plays a game in the morning, and I'll
find the game still running 12 hours later, after he's gone to bed.)
Given this behavior, it seems more secure
to ask for some sort of authentication as part of accepting
a deposit slip. This is essentially the way a real bank works, in
any event.
The analog of logging in would be identifying yourself to a guard as you were admitted to the bank. (Which might be a reasonable approach, it's just not the one I chose.) Note that there's nothing in this use case to prohibit the teller from remembering who Philip is. That is, it's within the scope of the use case for the customer to be somehow labeled as "trusted" so that subsequent transactions can be performed without needing to repeat the authentication process. The "trusted" attribute could be cancelled by a log out, or it could simply time out. (For example, you would become untrusted if two minutes elapsed without any activity within the bank.)
- (This note may not be clear to you until we start the actual object modeling, so don't worry it if it doesn't make sense, yet.) The Kid is, for the most part, an external object. That is, there is no programmatic object within the system that will represent the Kid; rather, the Kid is a physical user of the system. On the other hand, the notion of a Kid's identity will almost certainly be modeled, since some object in the system must handle authentication.
- There's a difference between "available funds" and
"current balance." (The latter doesn't reflect unauthorized
transactions.) Since the kid treats a deposit as a deposit,
regardless of whether or not it's authorized, the passbook
should display both values. In any event, it can't hurt to
teach kids how a "hold" works.
I'm not sure how best to present holds in the UI. One solution is for The deposit slip to be shown to any kids who look at their passbooks, but the deposit won't show up in the passbook proper until the deposit slip is authorized by a parent. Another possibility would be for the deposit to show up in the passbook like an authorized deposit, but with some visual indication (grey text?) that the deposit is being held.
The latter makes more sense, but this means that the parent-authorizing-current-deposit use case will probably be significantly different from the parent-authorizing-pending-deposits use case.
Note that, if the teller holds deposit slips for parent authorization, the kid will have to ask the teller to see the passbook so that the teller can display the held deposit slips as well as the passbook.
- Probably the best way to handle parent authorization is on the UI for the deposit slip itself. Maybe an "Authorized" box, which, when checked, pops up a small dialog onto which a signature can be entered. Another possibility is a "authorized signature" line on the deposit slip itself into which a parent can type a pass phrase. (Note that some indication that the transaction has been authorized—a facsimile of a signature, for example—should appear on an authorized deposit slip ). Don't print x's in the authorized-signature line (or at least replace the x's once the signature is verified); there's no point in giving away the number of characters in the passphrase.
- There are some access-control issues here. Someone in the role of Kid has permission to specify deposits, but not to authorize deposits. (An authorization causes the account balance and passbook to be updated.) Someone in the Parent role may both specify deposits and authorize deposits. The system must be able to distinguish between actors in these two roles—password authentication is adequate.
- Interest accumulates on held funds, even if these funds are not
accessible.
Probably the best way to handle interest is to think of the
passbook as a list of transactions, sorted by date. When a
deposit slip is authorized, it's inserted into the transaction
list in sorted order. Interest is then recomputed, starting
at the point immediately above the most-recently inserted
transaction. This way an unauthorized transaction effectively
doesn't accrue interest.
You want to show interest accrual on a daily basis, however, so it's not sufficient to list only transactions, as would a real-world passbook or bank statement. You really want a line item for every day. That's a lot of line items, though. A reasonable compromise might be to show the previous 30 days on a per-day basis, with the rest of the passbook looking like a standard bank statement that shows regular (but not daily) interest postings, perhaps one posting per week.
- There's currently no notion of logging in. Looking at the
scenarios, Philip is not likely to make several transactions
at once; in fact, it's more likely that he'll make a single transaction,
but forget to log off. (This is an observed behavior from my home
testing lab—Philip often plays a game in the morning, and I'll
find the game still running 12 hours later, after he's gone to bed.)
Given this behavior, it seems more secure
to ask for some sort of authentication as part of accepting
a deposit slip. This is essentially the way a real bank works, in
any event.
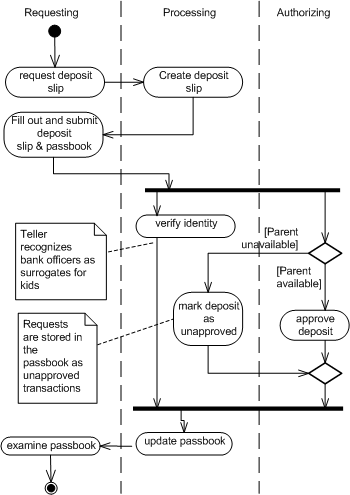
So that's the first one. Next month I'll present the others:
2.0 Kid Withdrawing funds from an Account (equivalent to 1.0?)
3.0 Kid Playing what-if games (equivalent to Parent examining kid account)
4.0 Parent Opening or Changing an Account
5.0 Parent Closing an Account
6.0 Parent authorizing prior deposits
6.1 Parent authorizing a single deposit (also a subcase of 1.0)
References
The notion of an object being defined by it's operations is discussed in Allen Holub, "What is an Object?" (JavaWorld: July, 1999). Subsequent articles in the series (all of which are indexed at /aiharticles.html) discuss how this philosophy is actually applied to real-world systems.
Workflow diagrams (along with the rest of UML) are described nicely in
Martin Fowler and Kendall Scott's
UML Distilled, 2nd Ed.
Notes
| 1 | Adele Goldberg and Kenneth Rubin, Succeeding with Objects: Decision Frameworks for Project Management (Reading, Addison Wesley: 1995; ISBN 0-201-62878-3), p. 19. This is a stunningly good book for managers who want to move their shops into an OO environment. |
| 2 | RUP (The Rational Unified Process) is described in Ivar Jacobson, Grady Booch, and James Rumbaugh, The Unified Software Development Process (Reading: Addison Wesley 1999; ISBN 0-201-57169-2). |
| 3 | XP (Extreme Programming) is described in Kent Beck, Extreme Programming Explained: Embrace Change (Reading, Addison-Wesley, 1999; ISBN: 0-201-61641-6). XP is controversial, but I expect that a lot of the controversy comes from people making assumptions about what Beck is talking about without having first read his book. XP and RUP actually integrate quite nicely, as described by Grady Booch in a draft Chapter of his new OO-Design book, found at http://www.objectmentor.com/publications/RUPvsXP.pdf. The ObjectMentor web site also has a wealth of useful material on this topic. |
| 4 | You can get a copy of my UML templates for Visio from the Goodies section of my web site . |
| 5 | Christopher Alexander, et. al. A Pattern Language: Towns, Buildings, Construction New York: Oxford University Press, 1977; ISBN 0-19-501919-9. |
| 6 | The "Bank of Allen" is a trademark of Allen I. Holub. This program, and the design thereof, is (c) 2000, Allen I. Holub. All rights reserved. |
| 7 | Steve McConnell wrote a great editorial in the March/April, 2000 issue of IEEE Software on the confusion of paperwork with progress. The editorial is called "Cargo Cult Software Engineering," and you can find it at http://computer.org/software/so2000/pdf/s2011.pdf. |
| 8 | Alan Cooper.
About Face: The Essentials of User Interface Design
(Foster City, Calif.: IDG Books, 1995; ISBN 1-56884-322-4).
It is ironic that the author of a great book about UI design is also the "father of Visual Basic," the tool responsible for many of the worst user interfaces ever foisted on the computing public. Cooper has a lot of opinions, some of which I agree with and some of which I don't. (In particular, I don't think of a program as a UI with intelligent warts hanging off of it, as Cooper seems to do). Nonetheless, Cooper is always entertaining, and there's a lot of good advice here. Most of the books on UI design are written either by programmers (who put the convenience of the programmer above the needs of the user) or graphic artists (who put things like "art," "impact," and "originality" above the needs of the user). In either case, the user looses. It's refreshing to read a book about UI design written by a knowledgable programmer who not only insists on putting the user first, but also has a good design sense. (Cooper Design's web site). |